Vercel AI SDK + LangChain + Upstash Vector:30 分钟打造你自己的 RAG 聊天机器人
- 作者
在当前的人工智能应用浪潮中,RAG(检索增强生成)技术正迅速崛起,成为焦点。本文将手把手教你如何使用 LangChain、OpenAI 和 Upstash 来构建一个强大的 RAG 查询系统。我们不仅会深入解析代码实现,还会带你全面了解整个查询过程的工作原理。请坐好扶稳,让我们快速实现一个 RAG 查询系统的原型。
整体架构
任何成功的聊天机器人的秘密武器正是其背后的数据。在我们的案例中,我们将一个网站作为数据源。为了高效地从目标网站收集数据,我们采用了自定义的Scrapy爬虫技术,将获取到的数据分块存储在Upstash Vector中。接下来,我们利用Vercel AI SDK,结合LangChain和OpenAI,与爬取的数据无缝对接,实现强大的RAG(retrieval-augmented generation)查询功能。
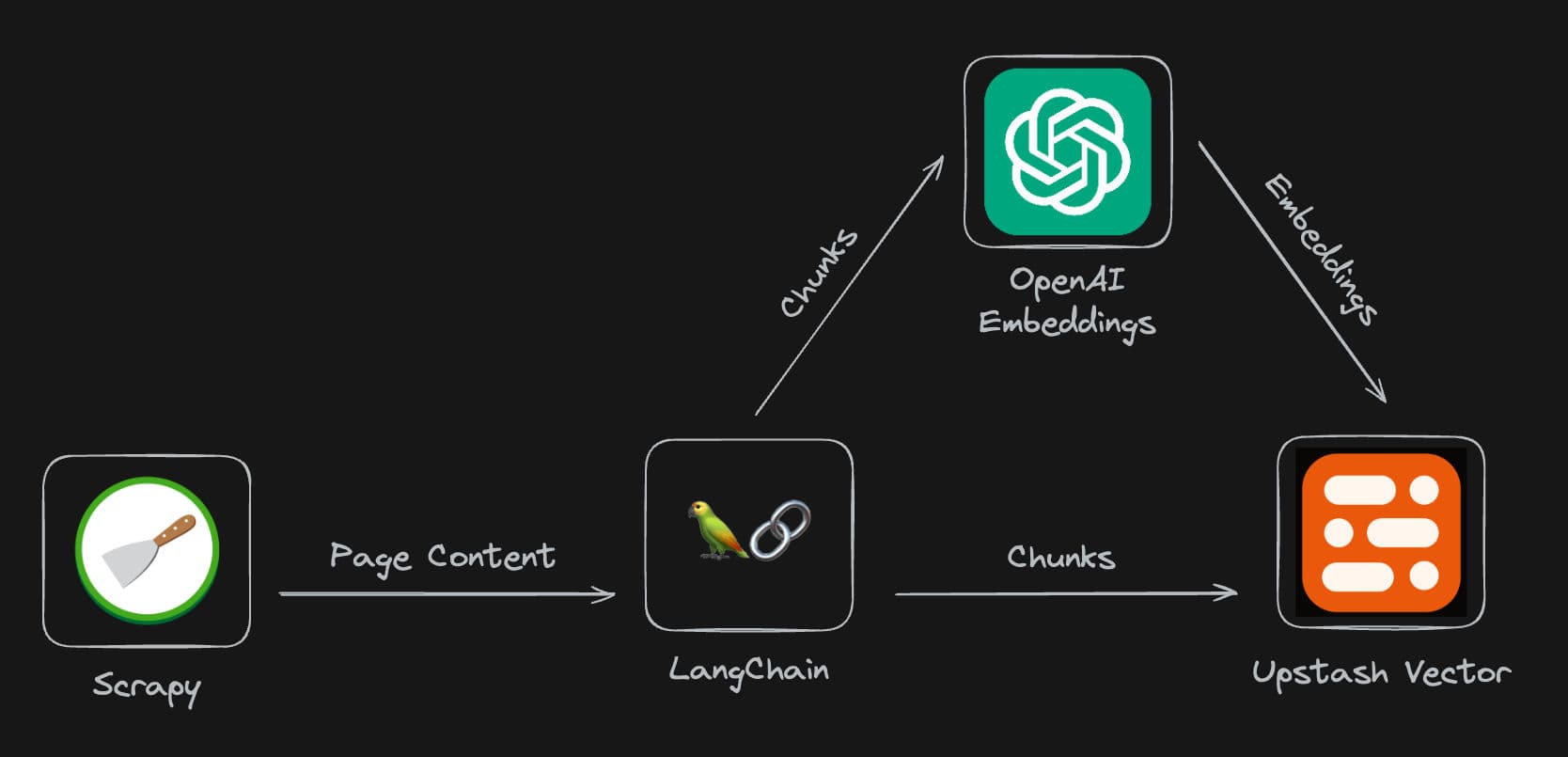
| 组件 | 技术栈 |
|---|---|
| 爬虫 | scrapy |
| 聊天机器人应用 | Next.js |
| 向量数据库 | Upstash Vector |
| LLM 编排 | Langchain.js |
| 生成模型 | OpenAI, gpt-3.5-turbo-1106 |
| 嵌入模型 | OpenAI, text-embedding-ada-002 |
| 文本流式传输 | Vercel AI |
| 速率限制 | Upstash Redis |
| 用户认证 | NextAuth |
系统概述
我们的 RAG 系统主要由以下几个部分组成:
- 数据爬虫
- 用户认证
- 速率限制
- 向量存储和检索
- AI 代理执行
- 流式响应
数据爬虫
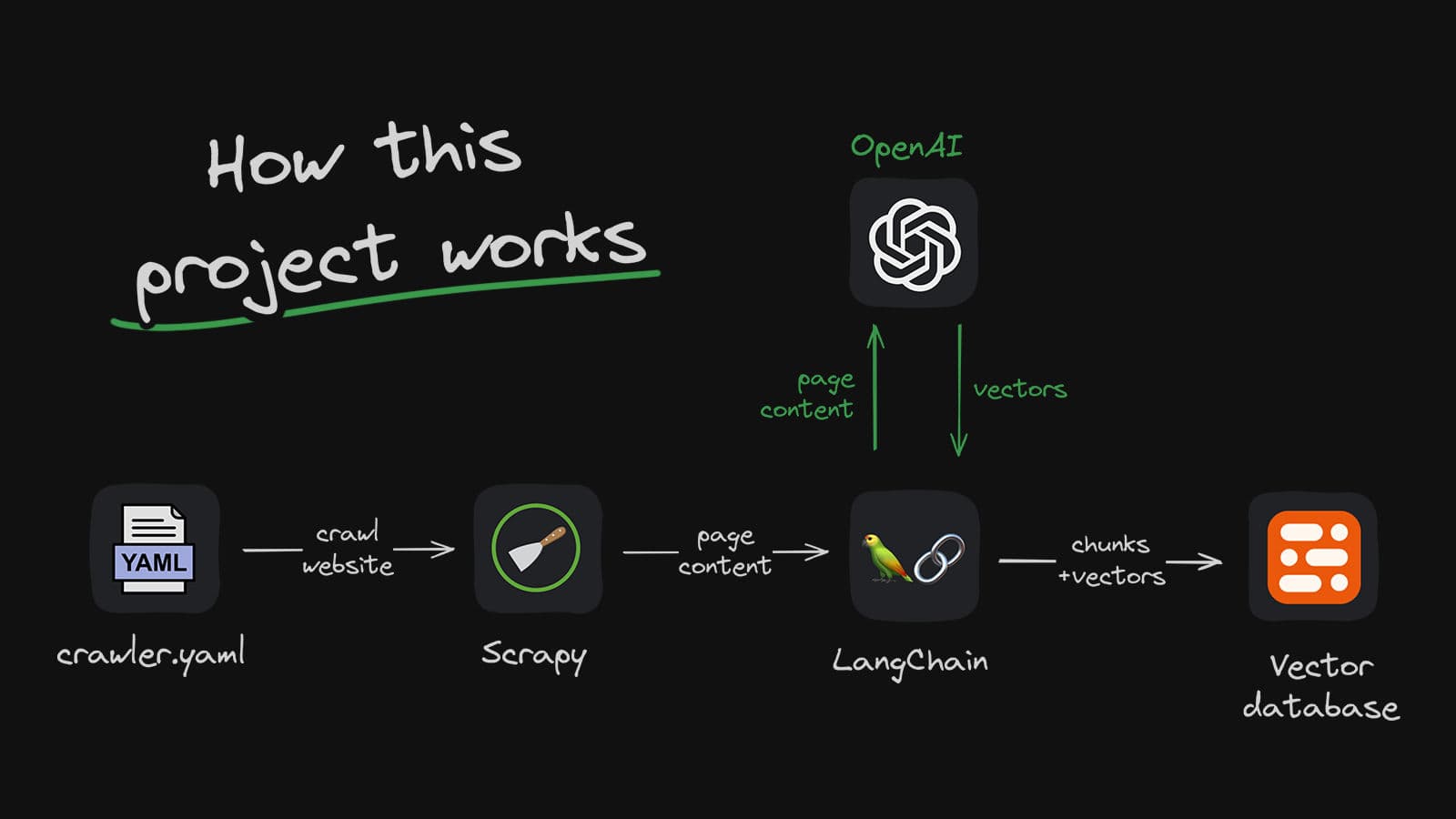
我们的项目需要一种简单的方法来填充 Upstash Vector。为此,我们创建了一个 crawler.yaml 文件。通过此文件,我们可以配置:
- 爬虫将从哪些 URL 开始抓取
- 链接提取器将匹配哪些链接
- 创建嵌入时将使用的 OpenAI 嵌入模型
- 我们的
RecursiveCharacterTextSplitter将如何将网页内容分割成文本块
crawler:
start_urls:
- https://www.some.domain.com
link_extractor:
allow: '.*some\.domain.*'
deny:
- "#"
- '\?'
- course
- search
- subjects
index:
openAI_embedding_model: text-embedding-ada-002
text_splitter:
chunk_size: 1000
chunk_overlap: 100
在爬虫里面,我们添加 UpstashVectorStore 类来处理文本块的嵌入并将其存储在 Upstash Vector 中。
from typing import List
from openai import OpenAI
from upstash_vector import Index
class UpstashVectorStore:
def __init__(
self,
url: str,
token: str
):
self.client = OpenAI()
self.index = Index(url=url, token=token)
def get_embeddings(
self,
documents: List[str],
model: str = "text-embedding-ada-002"
) -> List[List[float]]:
"""
给定文档列表,生成并返回嵌入列表
"""
documents = [document.replace("\n", " ") for document in documents]
embeddings = self.client.embeddings.create(
input = documents,
model=model
)
return [data.embedding for data in embeddings.data]
def add(
self,
ids: List[str],
documents: List[str],
link: str
) -> None:
"""
将文档列表添加到 Upstash Vector Store
"""
embeddings = self.get_embeddings(documents)
self.index.upsert(
vectors=[
(
id,
embedding,
{
"text": document,
"url": link
}
)
for id, embedding, document
in zip(ids, embeddings, documents)
]
)
完整的代码可以查看: https://github.com/hunterzhang86/fflow-web-crawler
用户认证
我们了使用 NextAuth 进行用户认证:
export const POST = auth(async (req: NextAuthRequest) => {
const user = req.auth;
if (!user) {
return new Response("Not authenticated", { status: 401 });
}
// ...
});
这确保了只有经过认证的用户才能访问我们的 API。
速率限制
为了防止 API 被滥用,我们使用 Upstash 的 Redis 实现了速率限制:
const ratelimit = new Ratelimit({
redis: redis,
limiter: Ratelimit.slidingWindow(5, "10 s"),
});
// 在请求处理中
const { success } = await ratelimit.limit(ip);
if (!success) {
// 返回速率限制响应
}
向量检索
我们使用 Upstash 的向量存储来存储和检索相关信息:
const vectorstore = new UpstashVectorStore(embeddings, {
index: indexWithCredentials,
});
const retriever = vectorstore.asRetriever({
k: 6,
searchType: "mmr",
searchKwargs: {
fetchK: 5,
lambda: 0.5,
},
});
这允许我们高效地检索与用户查询相关的信息。
AI Agent 执行
核心的 RAG 功能是通过 LangChain 的 AI Agent 实现的:
const agent = await createOpenAIFunctionsAgent({
llm: chatModel,
tools: [tool],
prompt,
});
const agentExecutor = new AgentExecutor({
agent,
tools: [tool],
returnIntermediateSteps,
});
代理使用检索工具来搜索相关信息,然后生成响应。
流式响应
在前端我们则通过 Vercel AI SDK 中的 useChat 实现了流式响应。通过 initialMessages,我们可以让应用程序从机器人的欢迎消息开始。onResponse 允许我们定义流结束时调用的函数。如果用户点击聊天界面中的建议问题,我们会调用 setInput 方法。
// page.tsx
import React, { useEffect, useRef, useState } from "react";
import { Message as MessageProps, useChat } from "ai/react";
// ...
export default function Home() {
// ...
const [streaming, setStreaming] = useState<boolean>(false);
const { messages, input, handleInputChange, handleSubmit, setInput } =
useChat({
api: "/api/chat",
initialMessages: [
{
id: "0",
role: "system",
content: `**Welcome to FFlow Next**`,
},
],
onResponse: () => {
setStreaming(false);
},
});
// ...
}
后端的接口我们也实现了流式响应:
const logStream = await agentExecutor.streamLog({
input: currentMessageContent,
chat_history: previousMessages,
});
// 创建一个 ReadableStream 来流式传输响应
const transformStream = new ReadableStream({
async start(controller) {
// 流式处理逻辑
}
});
return new StreamingTextResponse(transformStream);
这允许我们逐步向客户端发送生成的响应,而不是等待整个响应完成。.
结论
通过结合 LangChain、OpenAI 和 Upstash 的强大功能,不到 30 分钟即可构建了一个可扩展的 RAG 查询系统。这个系统不仅能够提供准确的信息检索,还能生成流畅的对话响应。
在实际应用中,您可能需要根据具体需求进行进一步的优化和定制。例如,您可以调整检索参数、优化提示模板,或者添加更多的工具来增强 AI 代理的能力。
文章里面涉及到的内容可以查看我的代码仓库 https://github.com/hunterzhang86/fflow-next ,实现的效果可以查看 www.fflowlink.com ,希望这篇文章能帮助您理解 RAG 系统的工作原理,并激发您在自己的项目中实现类似功能的灵感! 。
分享内容