Quick Start to RAG Chatbots:Using Vercel AI SDK, LangChain, and Upstash Vector in Just 30 Minutes
- Authors
Amid the current wave of AI applications, RAG (Retrieval-Augmented Generation) technology is rapidly emerging as a focal point. This article will guide you step-by-step on how to build a robust RAG query system using LangChain, OpenAI, and Upstash. Not only will we delve deep into the code implementation, but we will also help you fully understand how the entire query process works. Buckle up, and let's quickly prototype a RAG query system.
Overall Architecture
The secret weapon behind any successful chatbot lies in its underlying data. In our case, we use a website as the data source. To efficiently collect data from the target site, we employ custom Scrapy crawler technology and store the acquired data in chunks within Upstash Vector. Next, we leverage the Vercel AI SDK, integrated with LangChain and OpenAI, to seamlessly connect with the scraped data and implement powerful RAG (retrieval-augmented generation) query functionality.
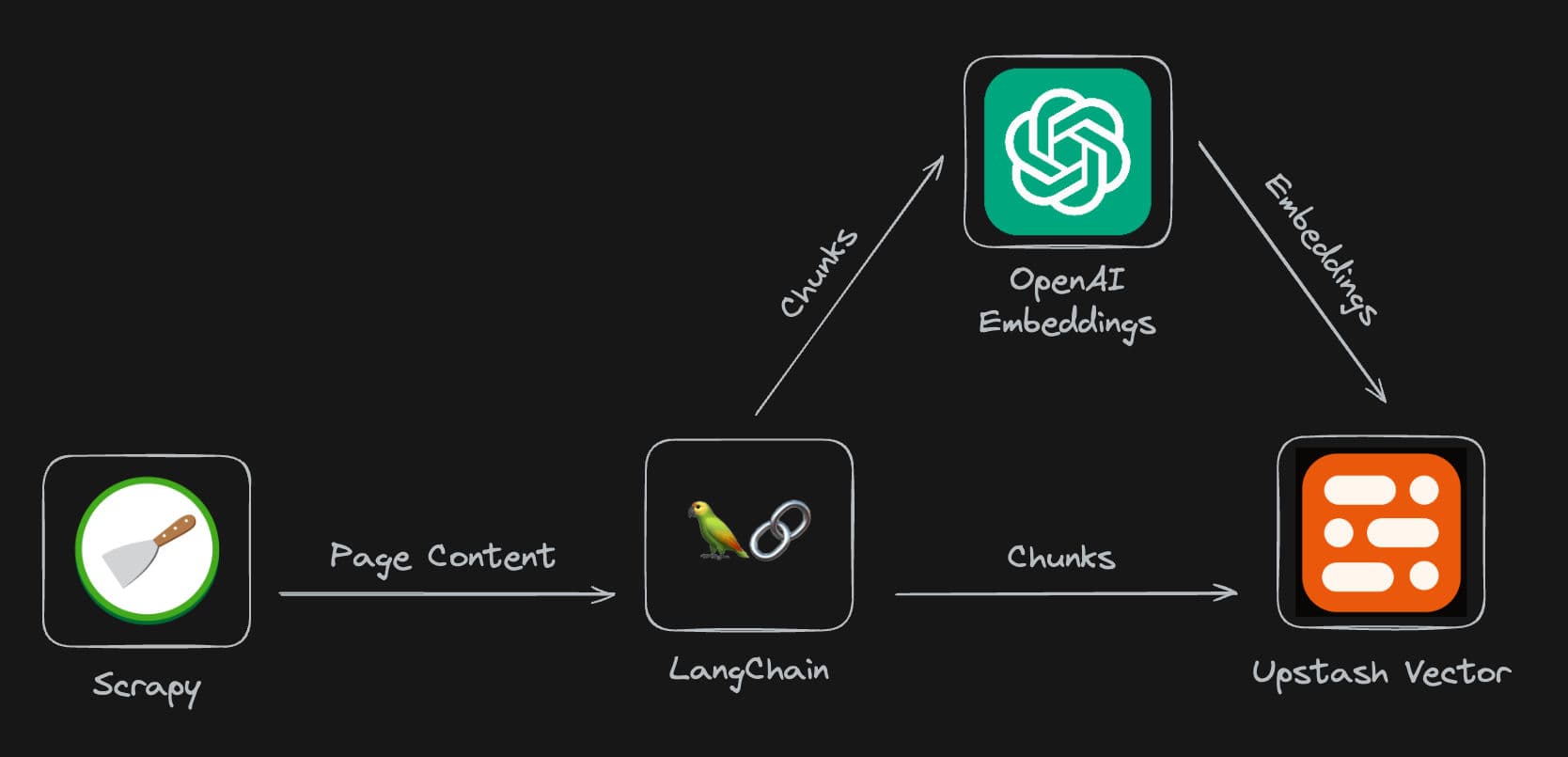
| Component | Tech Stack |
|---|---|
| Crawler | scrapy |
| Chatbot App | Next.js |
| Vector Database | Upstash Vector |
| LLM Orchestration | Langchain.js |
| Generation Model | OpenAI, gpt-4o |
| Embedding Model | OpenAI, text-embedding-ada-002 |
| Text Streaming | Vercel AI |
| Rate Limiting | Upstash Redis |
| User Authentication | NextAuth |
System Overview
Our RAG system mainly consists of the following components:
- Data Crawler
- User Authentication
- Rate Limiting
- Vector Storage and Retrieval
- AI Agent Execution
- Streaming Responses
Data Crawler
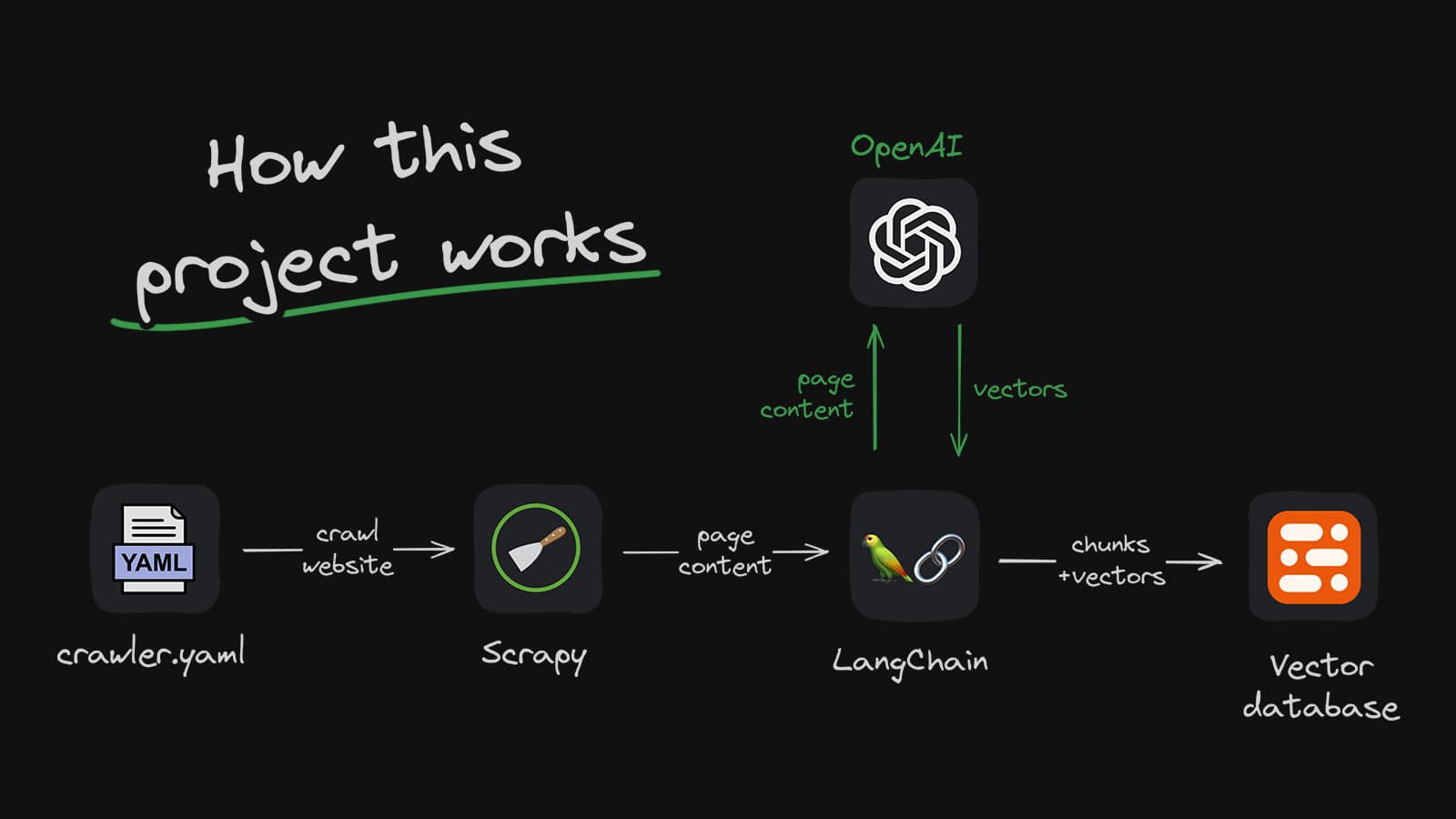
Our project requires a straightforward method to populate the Upstash Vector. To achieve this, we created a crawler.yaml file. This file allows us to configure:
- The URLs from which the crawler will start fetching data
- Which links the link extractor will match
- The OpenAI embedding model to be used when creating embeddings
- How our
RecursiveCharacterTextSplitterwill divide webpage content into text chunks
crawler:
start_urls:
- https://www.some.domain.com
link_extractor:
allow: '.*some\.domain.*'
deny:
- "#"
- '\?'
- course
- search
- subjects
index:
openAI_embedding_model: text-embedding-ada-002
text_splitter:
chunk_size: 1000
chunk_overlap: 100
Within the crawler, we add the UpstashVectorStore class to handle text chunk embeddings and store them in the Upstash Vector.
from typing import List
from openai import OpenAI
from upstash_vector import Index
class UpstashVectorStore:
def __init__(
self,
url: str,
token: str
):
self.client = OpenAI()
self.index = Index(url=url, token=token)
def get_embeddings(
self,
documents: List[str],
model: str = "text-embedding-ada-002"
) -> List[List[float]]:
"""
Given a list of documents, generate and return a list of embeddings.
"""
documents = [document.replace("\n", " ") for document in documents]
embeddings = self.client.embeddings.create(
input = documents,
model=model
)
return [data.embedding for data in embeddings.data]
def add(
self,
ids: List[str],
documents: List[str],
link: str
) -> None:
"""
Add a list of documents to the Upstash Vector Store.
"""
embeddings = self.get_embeddings(documents)
self.index.upsert(
vectors=[
(
id,
embedding,
{
"text": document,
"url": link
}
)
for id, embedding, document
in zip(ids, embeddings, documents)
]
)
The full code can be viewed at: https://github.com/hunterzhang86/fflow-web-crawler
User Authentication
We use NextAuth for user authentication:
export const POST = auth(async (req: NextAuthRequest) => {
const user = req.auth;
if (!user) {
return new Response("Not authenticated", { status: 401 });
}
// ...
});
This ensures that only authenticated users can access our API.
Rate Limiting
To prevent API abuse, we implement rate limiting using Upstash's Redis:
const ratelimit = new Ratelimit({
redis: redis,
limiter: Ratelimit.slidingWindow(5, "10 s"),
});
// During request processing
const { success } = await ratelimit.limit(ip);
if (!success) {
// Return rate limit response
}
Vector Retrieval
We use Upstash's vector store to store and retrieve relevant information:
const vectorstore = new UpstashVectorStore(embeddings, {
index: indexWithCredentials,
});
const retriever = vectorstore.asRetriever({
k: 6,
searchType: "mmr",
searchKwargs: {
fetchK: 5,
lambda: 0.5,
},
});
This allows us to efficiently retrieve information relevant to user queries.
AI Agent Execution
The core RAG functionality is implemented using LangChain's AI Agent:
const agent = await createOpenAIFunctionsAgent({
llm: chatModel,
tools: [tool],
prompt,
});
const agentExecutor = new AgentExecutor({
agent,
tools: [tool],
returnIntermediateSteps,
});
The agent uses retrieval tools to search for relevant information and then generates a response.
Streaming Responses
On the frontend, we implement streaming responses using the useChat feature in the Vercel AI SDK. With initialMessages, we can start the application with a welcome message from the chatbot. The onResponse function allows us to define actions to be taken once the stream ends. If the user clicks on a suggested question in the chat interface, we call the setInput method.
// page.tsx
import React, { useEffect, useRef, useState } from "react";
import { Message as MessageProps, useChat } from "ai/react";
// ...
export default function Home() {
// ...
const [streaming, setStreaming] = useState<boolean>(false);
const { messages, input, handleInputChange, handleSubmit, setInput } =
useChat({
api: "/api/chat",
initialMessages: [
{
id: "0",
role: "system",
content: `**Welcome to FFlow Next**`,
},
],
onResponse: () => {
setStreaming(false);
},
});
// ...
}
We also implement streaming responses on the backend:
const logStream = await agentExecutor.streamLog({
input: currentMessageContent,
chat_history: previousMessages,
});
// Create a ReadableStream to stream the response
const transformStream = new ReadableStream({
async start(controller) {
// Streaming logic
}
});
return new StreamingTextResponse(transformStream);
This allows us to send generated responses to the client incrementally, rather than waiting for the entire response to complete.
Conclusion
By combining the powerful features of LangChain, OpenAI, and Upstash, it is possible to build a scalable RAG query system in less than 30 minutes. This system not only provides accurate information retrieval but also generates smooth conversational responses.
In practice, you may need to further optimize and customize the system based on your specific requirements. For instance, you can adjust retrieval parameters, optimize prompt templates, or add more tools to enhance the AI agent's capabilities.
You can check out the content mentioned in this article in my code repository at https://github.com/hunterzhang86/fflow-next, and view the implementation at www.fflowlink.com. I hope this article helps you understand the workings of RAG systems and inspires you to implement similar functionality in your own projects!
Share this content