RAG 快速入门:30 分钟手把手教你实现 ChatPDF
- 作者
在 AI 热潮中,RAG 俨然成为了众多 LLM 应用的核心技术。无论是 AI 搜索,还是 ChatPDF 等文档对话工具,背后几乎都离不开 RAG。
但 RAG 究竟是什么?如何在 30 分钟内自己实现一个 ChatPDF?
本指南将从 0 到 1 带你构建一个能够“与 PDF 聊天”的应用,帮助你掌握 RAG 的核心概念和实现步骤。
什么是 RAG?
RAG 的核心思想是在生成回答前,先从外部知识库中“检索”相关信息,然后将这些信息与用户的问题一起发送给大语言模型 (LLM),以便生成更准确的回答。
为什么要使用 RAG?
- 🚀 实时性:LLM 不必依赖模型中的静态知识,而是从外部数据库中动态查询。
- 🧠 准确性:通过结合外部的“实时上下文”,生成的回答更加精准。
- 💾 可扩展性:只需更新外部数据库,而不需要重新训练模型。
RAG 已被应用于多个场景,如:
- ChatPDF:与 PDF 文档聊天
- 企业知识库:对公司文档、领域知识、手册、文件进行问答。
- AI 搜索:RAG 可以改进搜索结果,使其更准确和直接。
RAG 是如何工作的?
要理解 RAG,我们需要了解两个核心步骤:
- 检索 (Retrieval):从外部数据库中检索相关文档,例如 PDF 中的段落、文档块等。
- 生成 (Generation):将这些文档和用户输入一起交给 LLM,生成一个基于文档内容的回答。
RAG 的工作流程如下:
- 📝 用户提问:用户向系统输入一个问题。
- 🔍 查询重写:将用户输入的查询重写为 5 个搜索查询(确保查询多样化)。
- 📚 文档检索:使用全文搜索和向量搜索从 PDF 中获取相关的“文档片段”。
- ⚙️ 重排融合:使用重排算法对检索到的段落排序。
- 🤖 生成答案:将检索到的段落与用户输入一起发送给 LLM,生成最终回答。
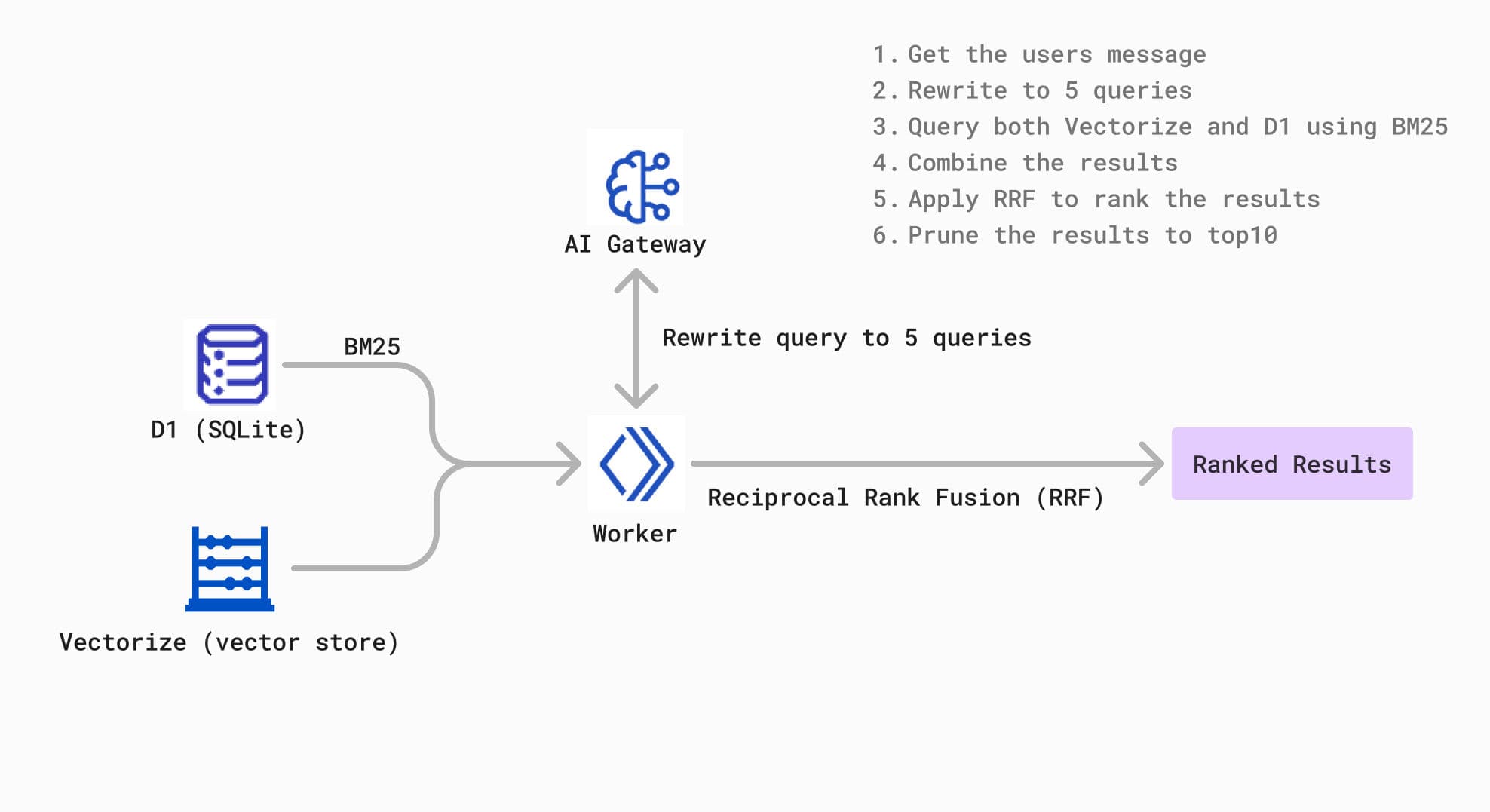
用 RAG 实现 ChatPDF:所需工具
为了方便,我们将使用 Cloudflare 的底层能力来实现 ChatPDF:
| 工具 | 作用 |
|---|---|
| Cloudflare D1 | 用于全文搜索,支持 BM25 排序 |
| Cloudflare Vectorize | 用于语义搜索,支持嵌入向量搜索 |
| LLM | 生成基于上下文的自然语言回答 |
| Cloudflare Pages | 部署 RAG 应用,使其可在云端运行 |
| Cloudflare R2 | 存储上传的 PDF 文件 |
这些工具的组合能够实现高效的“关键字搜索 + 语义搜索”,形成一个混合 RAG 系统,大幅提升检索效果。
手把手实现 ChatPDF
接下来,我们将从 0 开始实现一个完整的 ChatPDF 应用。
1️⃣ 重写用户查询
RAG 的第一个重要环节是将用户的输入通过大模型重写成 5 条多样化的查询,这里理论上模型能力越强效果越好,[可以通过这个链接找到目前比较好用的模型列表](聊天模型 - 分类 | AI星图),我们这里使用 Cloudflare AI Gateway 里面的 llama 模型。
实现步骤:
- 调用 LLM 生成 5 条与用户问题相关的多样化查询。
- 确保查询语义相似,但措辞不同,以覆盖更多的可能性。
示例代码:
async function rewriteToQueries(content: string): Promise<string[]> {
const prompt = `Given the following user message, rewrite it into 5 distinct queries that could be used to search for relevant information. Each query should focus on different aspects or potential interpretations of the original message. No questions, just a query maximizing the chance of finding relevant information.
User message: "${content}"
Provide 5 queries, one per line and nothing else:`
const { response } = await hubAI().run('@cf/meta/llama-3.1-8b-instruct', { prompt }) as { response: string }
const regex = /^\d+\.\s*"|"$/gm
const queries = response
.replace(regex, '')
.split('\n')
.filter(query => query.trim() !== '')
.slice(1, 5)
return queries
}
2️⃣ 检索文档片段
系统会将 5 条查询发送到 Cloudflare D1 和 Cloudflare Vectorize,同步执行全文搜索和语义搜索,关键字搜索 + 语义搜索 的搭配,形成一个混合 RAG 系统,可以比较有效的提升检索的精准度。
示例代码:
async function searchDocumentChunks(searchTerms) {
const queries = searchTerms.map(term => sql`
SELECT document_chunks.*, document_chunks_fts.rank
FROM document_chunks_fts
WHERE document_chunks_fts MATCH ${term}
ORDER BY rank DESC
LIMIT 5
`)
const results = await Promise.all(queries.map(query => useDrizzle().run(query)))
return results.flat().sort((a, b) => b.rank - a.rank).slice(0, 10)
}
3️⃣ 重排融合
使用 rerank 算法将全文搜索和向量搜索的结果合并,这里使用最简单的递归排序融合 (Reciprocal Rank Fusion, RRF) 算法实现,如果想要效果好的话可以基于Cohere 的重排模型。
示例代码:
function performReciprocalRankFusion(fullTextResults, vectorResults) {
const k = 60
const scores = {}
fullTextResults.forEach((result, index) => {
scores[result.id] = (scores[result.id] || 0) + 1 / (k + index)
})
vectorResults.forEach(result => {
result.matches.forEach((match, index) => {
scores[match.id] = (scores[match.id] || 0) + 1 / (k + index)
})
})
return Object.entries(scores)
.map(([id, score]) => ({ id, score }))
.sort((a, b) => b.score - a.score)
}
4️⃣ 生成回答
最后,将用户的原始问题和检索到的文档上下文一起发送给 LLM,生成人类可读的回答。
示例代码:
const SYSTEM_MESSAGE = `You are a helpful assistant that answers questions based on the provided context. When giving a response, always include the source of the information in the format [1], [2], [3] etc.`
async function processUserQuery({ sessionId, messages }) {
messages.unshift({ role: 'system', content: SYSTEM_MESSAGE })
const lastMessage = messages[messages.length - 1].content
const queries = await rewriteToQueries(lastMessage)
const [fullTextResults, vectorResults] = await Promise.all([
searchDocumentChunks(queries),
queryVectorIndex(queries, sessionId)
])
const mergedResults = performReciprocalRankFusion(fullTextResults, vectorResults)
const relevantDocs = await getRelevantDocuments(mergedResults.map(r => r.id))
const response = `Relevant context from attached documents: \n${relevantDocs.map(doc => doc.text).join('\n\n')}`
return { messages: [...messages, { role: 'assistant', content: response }] }
}
总结
在 30 分钟内,您已经学习了如何从头实现一个 RAG 系统,并将其应用到 ChatPDF 中。通过掌握 RAG,您可以轻松构建企业知识库、ChatPDF、AI 搜索等之前个人非常难以实现工具,让我们享受大模型带来的便利。
相关的代码可以查看 GitHub - RihanArfan/chat-with-pdf: Chat with PDF lets you ask questions to PDF documents. Built and deployed with NuxtHub, and powered by Cloudflare Workers AI and Vectorize. 和 GitHub - RafalWilinski/cloudflare-rag: Fullstack "Chat with your PDFs" RAG (Retrieval Augmented Generation) app built fully on Cloudflare 两个网站。
分享内容